Contextual Multimodal Integration
- Categories: Interaction, AI, Publication
- Years: 2004-2025
-
Keywords:multimodal interaction, speech, gesture, Maximum Entropy classification, Genetic Algorithms, contextual input
Background
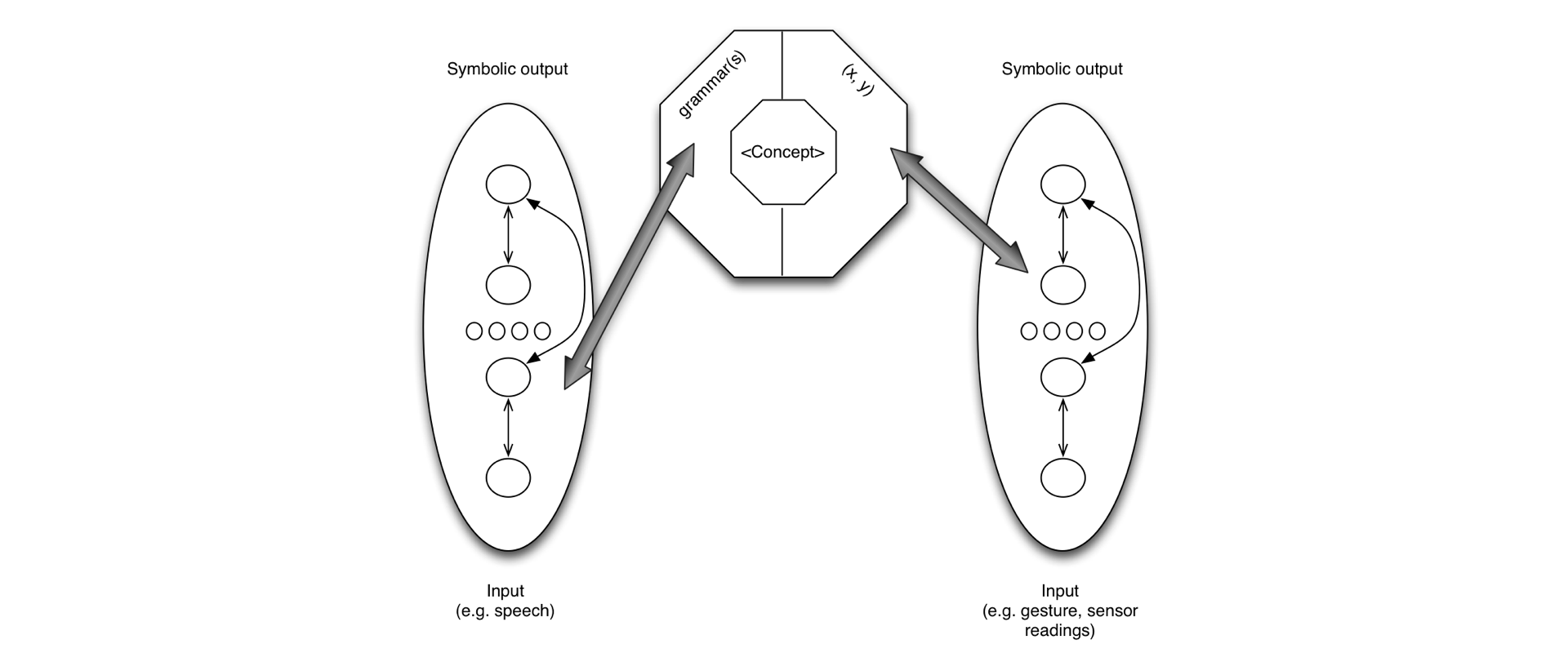
Multimodal integration is an essential part of any multimodal dialogue system. By multimodal input we refer to explicit and implicit inputs:
- explicit modalities are user generated speech, gesture, touch, etc. inputs, while
- implicit modalities are bits of information flowing in from various sensors, contextual or location information sources, usage history, personal preferences, etc.
and even bio signals in case of wearables or embedded medical products.
The main point here is that explicit and implicit inputs are equal from the system's task execution perspective,
thus they require similar handling methods and can be fused into a unified semantic representation.
Started back in 2003-2004, during a sabbatical year at MIT's Spoken Language Systems Group as a Visiting Scientist,
and then again picked up for lumila's multimodal journaling concept for parents of premature babies.
Earlier works
Typical solutions are ad-hoc approaches, with no dedicated integration module, only a hard-coded piece that fuses various user inputs.
These are usually rule-based solutions and thus do not scale.
More sophisticated approaches are linguistically motivated ones (unification grammar-based, case frames)
or originate from classification/model-based implementations (voting using agents, finite-state transducers).
Some statistical approaches are available as well. And with the recent advancements in deep learning for neural networks,
fusing multimodal, contextual and sensor inputs into a single semantic representation will follow what audio-visual signal fusion has already demonstrated.
While multimodal interaction has been on the research agenda for more than three decades,
multimodal integration itself is an often overlooked topic – thus room for research.
Good overviews of various integration approaches can be found in the book of
Delgado & Araki (2005),
and in the comprehensive survey by Denis Lalanne et al. (2009).
Project
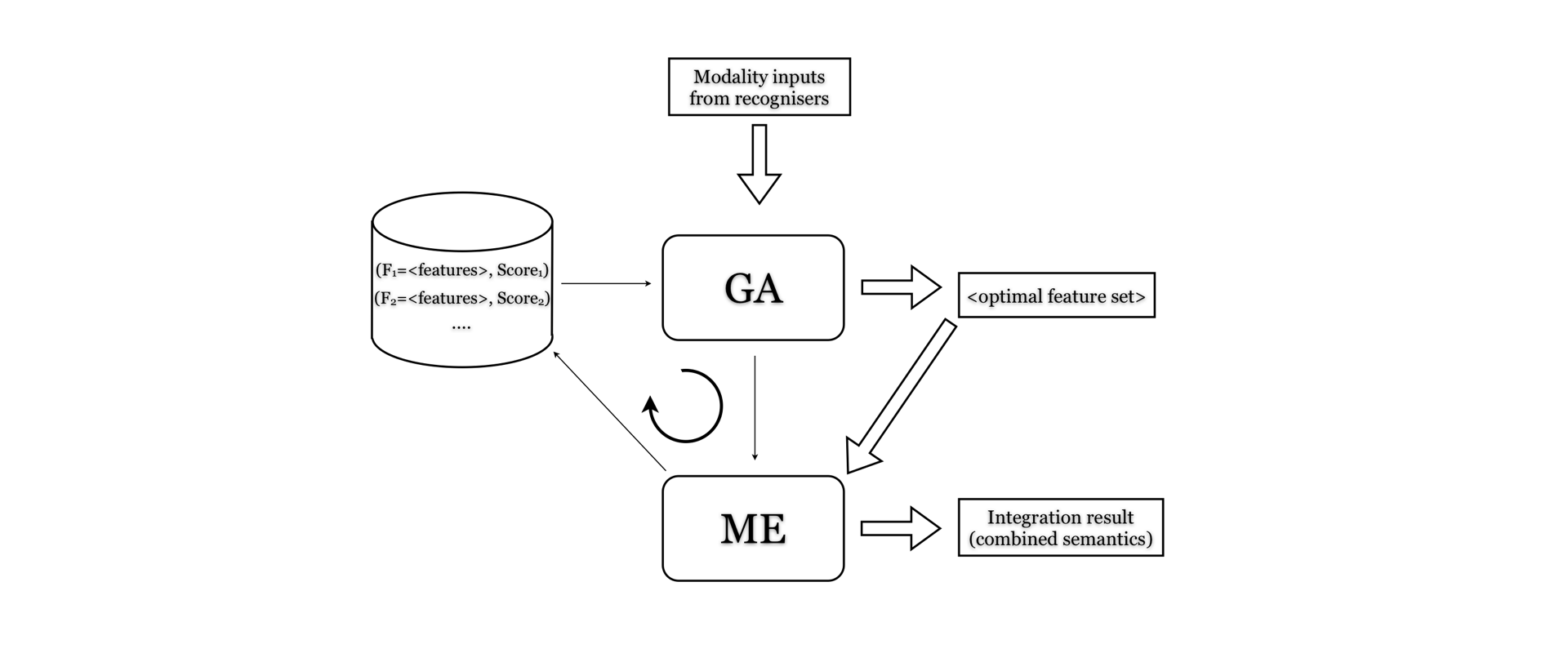
The integration problem was tackled from a linguistic perspective, and used a Maximum Entropy
based classification for fusing speech and gesture modalities with available contextual information.
The whole classification method is embedded into a Genetic Algorithm-based iteration that aims to find the optimal feature set for the classifier.
The first results on a larger speech-gesture database were encouraging and indicated
that an accuracy of over 90% can be achieved with Maximum Entropy based classification using 3-5 features only.
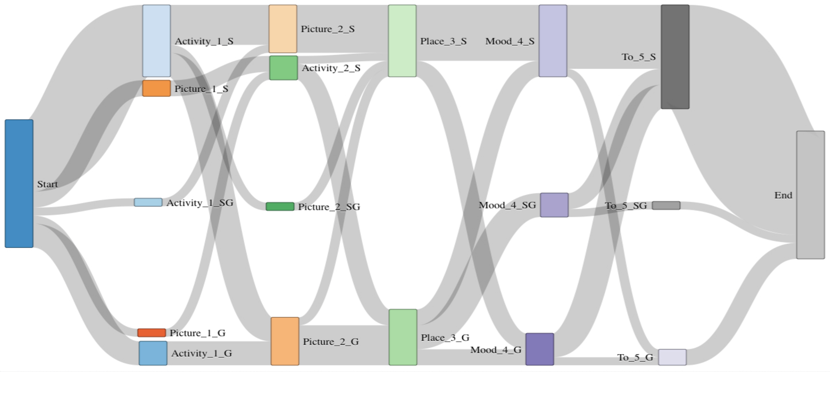
For the parental multimodal journaling use case for lumila,
a 96.38% average accuracy was achieved with 3.9% point standard deviation for the 6 folds
of the randomly selected training and evaluation sets.
The users' task was to use multimodal inputs to record into a diary the daily developmental data of their babies.
The results will be published in a journal article, currently in submission.
Next
The work for lumila continues, the goal is to bring multimodal interface capabilities to the parental engagement platform. One of the feedbacks from the large scale user study was that parents do not want to spend their precious time bedside by staring at and typing into mobile devices, they want to focus on their baby's care instead. One more reason to make interaction seamless.
References
- Virtual Modality (HLT-NAACL 2004 Workshop)
- A contextual multimodal integrator (ICMI 2006)
- Designing Multimodal Tools for Parents of Premature Babies (CHI 2016 Workshop)
- Multimodal Journaling as Engagement Tool for Parents of Premature Babies (Informatics for Health and Social Care, Taylor & Francis, 2025)